
por Huenei IT Services | Sep 20, 2023 | Inteligencia Artificial
Las organizaciones buscan constantemente formas de promover la productividad, optimizar los procesos y mejorar la experiencia del cliente; la IA generativa las está ayudando a lograrlo.
La IA generativa puede resultar particularmente útil en aplicaciones de software empresarial de la mano de las siguientes técnicas:
- Análisis de datos: La IA generativa se puede utilizar para analizar grandes cantidades de datos e identificar patrones y tendencias. Esto puede ayudar a las empresas a tomar mejores decisiones y optimizar sus operaciones. Por ejemplo, la IA generativa se puede utilizar para analizar datos de clientes e identificar patrones y preferencias de compra; esto permite a las empresas adaptar sus estrategias de marketing en función de grupos de clientes específicos.
- Personalización: La IA generativa se puede utilizar para personalizar la experiencia del usuario en las aplicaciones mediante la generación de contenido personalizado. Por ejemplo, una aplicación de noticias puede generar artículos de noticias personalizados para cada usuario en función de sus intereses y hábitos de lectura.
- Capacitación: La IA generativa se puede utilizar para crear contenido de capacitación personalizado sobre diversos temas para cada departamento de su organización. (Equipo de ventas, capacitación técnica, etc.)
- Mantenimiento predictivo: La IA generativa se puede utilizar para predecir fallas de equipos y necesidades de mantenimiento mediante el análisis de datos de sensores y otras fuentes. Esto puede ayudar a las empresas a evitar costosos tiempos de inactividad y reducir los costos de mantenimiento, dado que el mantenimiento se realiza únicamente cuando es necesario.
- Regionalización: La IA generativa se puede utilizar para regionalizar su aplicación en diferentes idiomas y ampliar su alcance global.
En general, la IA generativa puede ayudar a las empresas a optimizar las operaciones, reducir costos y tomar mejores decisiones aprovechando el poder del análisis de datos y el aprendizaje automático. Cabe destacar que las empresas deben ejercer un control de calidad sobre el contenido generado para garantizar su precisión y coherencia.
Como proveedor de servicios de desarrollo basados en modelos de OpenAI, podemos ayudarlo a crear modelos personalizados que garanticen resultados reales y lleven su negocio a nuevas alturas.
As a provider of OpenAI model-powered development services we can help you create custom models that deliver real results and take your business to new heights.

por Huenei IT Services | Feb 4, 2023 | Outsourcing
Para impulsar tu negocio, es clave que conozcas diferentes modalidades de subcontratación para que comprendas si es outsourcing lo que estás necesitando. Después de todo, para mejorar el rendimiento de tu empresa y tus equipos, ¡es esencial tomar las decisiones correctas!
En este artículo, te contaremos por qué deberías pensar en contratar los servicios de Staff Augmentation y Managed Services.
Staff Augmentation vs Managed Services: Todo lo que tienes que saber.
En primer lugar, cabe señalar que en el mundo del IT es clave entender la importancia de la externalización de personal. Es decir, cada vez más empresas necesitan servicios para potenciar sus resultados. Y esto plantea la pregunta de qué modelo implementar, especialmente entre Staff Augmentation y Managed Services.
Pero, ¿en qué consiste cada uno? Aquí están los detalles principales.

¿Qué es Staff Augmentation?
En primer lugar, es fundamental definir el proceso de Staff Augmentation. Según Icorp. consiste en la incorporación de un colaborador a la plantilla interna, siempre y cuando este individuo no represente un empleado contratado por la empresa. Es decir, estos empleados serán una “ayuda” por un tiempo concreto, para determinados fines.
En otras palabras, éstos no son empleados directos de la empresa. Si bien trabajarán en conjunto con los empleados de tiempo completo de la empresa, no representarán un aumento en el headcount.
¿Y cuáles son sus ventajas? Pues una de las más importantes es que reduce el tiempo de contratación. Cuando agregas empleados internos de “tiempo completo” a tu personal, generalmente tienes que pasar por diferentes procesos de recruiting.
Al contratar estos servicios, el tiempo de reclutamiento se reduce significativamente. Esto es más beneficioso especialmente cuando los trabajadores ya conocen esta metodología y están acostumbrados a trabajar bajo el sistema de Staff Augmentation. A su vez, esto implica una nueva ventaja: la flexibilidad de contratación.
Hoy en día, los procesos de trabajo son dinámicos y cambian constantemente. Por ello, en muchas ocasiones una empresa termina contratando personal para tareas específicas. ¡Pero esta metodología de outsourcing puede ayudarte a no aumentar tu headcount! Por ejemplo, si tienes pocos trabajos relacionados con Blockchain en tu empresa de TI, puede que no valga la pena contratar empleados a tiempo completo.
Por otro lado, adherirse a esta modalidad supondrá que, ante cualquier proyecto que pueda surgir para Cloud, podrás contratar los servicios de Staff Augmentation. Y a su vez, esto supondrá un beneficio económico. No gastarás dinero en un puesto que no necesitas y, al mismo tiempo, podrás aprovechar cualquier encargo que te surja de un cliente para esta área de especialización.
¿Qué son los Managed Services?
Pasemos a hablar de los Managed Services, también conocidos como Servicios Gestionados. Según Root Stack, esta es otra forma efectiva de trabajar en una empresa, que consiste en contratar a un proveedor de servicios de tecnología. Esto significa que ellos se encargarán de administrar el proyecto de desarrollo.
Es un modelo de trabajo muy utilizado por las empresas ya que ahorra tiempo al cliente. De esta forma, al delegar el desarrollo a una empresa especializada en TI, ya no tendrás que preocuparte por plazos ni tiempos de entrega, ya que otra empresa, con su equipo de trabajo, supervisará los procesos.
Sin embargo, algunos empresarios a veces no pueden entender el valor de este formato de contratación: las empresas que quieren estar al tanto de cada detalle del proyecto pueden sentirse inseguras. Después de todo, significa delegar toda la responsabilidad a otra empresa. Sin embargo, siempre es posible utilizar un documento técnico para monitorear el progreso de cada entrega. Es importante que confíes en el proveedor para poder delegar con tranquilidad.
Este es un sistema perfecto para aquellos sectores que no son prioritarios para la empresa y que demandan demasiado tiempo “innecesario”. Por ejemplo, si tu empresa se enfoca en cierta [área específica, como podría ser marketing y publicidad, puedes delegar el desarrollo de TI para enfocarse al 100% en tu core business, generando mayores beneficios económicos.
En conclusión… ¿Qué te recomendamos en Huenei?
Ambas estructuras de trabajo tienen sus ventajas y pueden ayudarte a alcanzar tus objetivos de forma más eficaz. Desde nuestra experiencia, en Huenei consideramos que Managed Services es una alternativa más acorde que los Augmented Teams para empresas cuyo eje de negocio no es el desarrollo de software. Los Managed Services te permitirán delegar la totalidad del proyecto a una empresa con amplia experiencia en gestión de procesos de desarrollo, como Huenei. De esta forma, podrás estar tranquilo de que el resultado será excelente.
En todos los casos será necesario contratar a un proveedor ético, confiable y con experiencia en el mercado. En Huenei llevamos años trabajando ofreciendo a nuestros clientes el mejor servicio. Tenemos el orgullo de haber ayudado a empresas de todo el mundo a alcanzar sus objetivos de negocio brindando servicios de desarrollo de software en diferentes modalidades, como Staff Augmentation y Managed Services. Puedes revisar nuestros casos de estudio para conocer nuestra experiencia en el campo.
En resumen, ahora conoces la diferencia entre Staff Augmentation y Managed Services. Lo importante es que puedes utilizar cada método en los casos que más te convengan. ¡Esperamos que este artículo haya sido útil!

por Huenei IT Services | Feb 4, 2023 | Desarrollo de Software
¿Estás interesado en mejorar el desarrollo de software de tu empresa? Bueno, puedes aprovechar algunas metodologías interesantes para aumentar la eficiencia, la productividad y la calidad de tus entregas, ¡y una de ellas podría ser el desarrollo rápido de aplicaciones! Te contamos todos los detalles al respecto.
Qué es el Desarrollo Rápido de Aplicaciones (DRA)?
Según Microsoft, el Desarrollo Rápido de Aplicaciones (DRA), también conocido por su nombre en inglés, Rapid Application Development (RAD), surgió en 1991, desarrollado por James Martin. En este momento, se ha convertido en una de las metodologías de desarrollo más populares dentro de las metodologías ágiles, ya que cada vez más empresas la adoptan.
Sin embargo, esta metodología se basó en el trabajo realizado por Scott Schultz en la década de 1980. La idea es trabajar de forma interactiva, construir prototipos y utilizar herramientas CASE, para mejorar la usabilidad, utilidad y velocidad de ejecución de todos los desarrollos.
Por lo tanto, DRA es un enfoque que busca enfatizar la estructura organizada del trabajo. La creencia básica es simple: cuanto mayor sea la organización, mejores serán los resultados. Aunque es una metodología algo flexible, el secreto es la constancia. Esta es una de las variables que permiten aumentar la calidad de las entregas.

¿Cuáles son los pasos del modelo DRA?
Habiendo revisado los puntos anteriores, seguramente que ahora quieres conocer las etapas del modelo DRA. Según CodeBots, 4 etapas definen esta metodología. Veámoslas a continuación:
Definición y especificación de los requerimientos del proyecto.
En esta etapa, es necesario definir y especificar los requisitos del proyecto. Por ejemplo, ¿cuáles son las expectativas y los objetivos del desarrollo de software? ¿Existen presupuestos o plazos específicos? Cuando se han establecido correctamente, es el momento de aprobarlos o reformularlos, si fuera necesario.
Inicio del diseño de los prototipos
Luego, es necesario desarrollar los prototipos. La idea es tener una conversación cercana con el cliente, para explicarle cuál es el estado del desarrollo. Se debe establecer en qué momento (aproximadamente) habrá una primera versión funcional del software. ¡Pero ten cuidado! Esto no significa que será la versión final.
Recopilación de opiniones de los usuarios
Una vez que se desarrolla el prototipo, debes comprender qué es lo que los usuarios opinan de él. ¿Funciona bien? ¿Tiene muchos errores? La idea es crear un producto final de la más alta calidad posible. Por esta razón, es clave prestar atención a los comentarios que recibes del cliente y de los sujetos de prueba.
Testeo y presentación final de la app
Finalmente, tendrás que hacer todo tipo de pruebas de usabilidad y funcionamiento para asegurarte de que el lanzamiento será exitoso. La clave está en satisfacer las necesidades del cliente, por lo que hay que probar el código una y otra vez hasta que funcione a la perfección. Además, ten en cuenta que siempre habrá posibles mejoras o errores que aparecerán más adelante y tendrás que corregirlos.

¿Cuáles son las ventajas de esta metodología?
Ahora bien, ¿cuáles son las ventajas de esta metodología? Aquí están los más importantes:
Entrega más rápida
Este es uno de los beneficios más destacados. La metodología DRA promete una entrega de software mucho más rápida. Al ser iterativo, es posible alcanzar el objetivo final más rápido. Y esto finalmente se traduce en una mayor satisfacción del cliente, pero también en una etapa de producción más veloz.
Ajustes rápidos y reducción de errores
Todo esto deriva en una mayor rapidez de corrección de posibles errores. Esta metodología busca encontrar (y solucionar) problemas a medida que avanza el desarrollo. Gracias a la metodología DRA, todos estos ajustes intermedios suelen ser mucho más eficientes, ¡y los errores también son menos frecuentes!
Disminución de los costes de desarrollo
La metodología DRA puede acortar el tiempo de desarrollo de un proyecto. La ventaja es que, al trabajar por etapas, no es necesario hacer demasiadas correcciones una vez lanzado el producto final. Esta decisión se traduce en menores costos de desarrollo, ya que el trabajo tiende a ser mucho más eficiente.
Mayor participación empresarial
Al usar DRA, el trabajo se basará en involucrar al negocio y al usuario final. El desarrollo se actualizará con frecuencia, lo que significa que el producto se puede pulir hasta el más mínimo detalle. ¿El resultado? El producto final estará muy cerca de lo que el cliente quiere. En otras palabras, también tendrá una mejor satisfacción del cliente final.
Software más utilizable
La metodología DRA también toma como punto de partida qué quiere y necesita el usuario. En consecuencia, todos los esfuerzos se concentran en las funcionalidades principales. Entonces, el producto final se vuelve mucho más funcional, ya que las características secundarias no son 100% relevantes.
Mejor control de riesgos
Finalmente, se debe considerar que con DRA es posible identificar factores de riesgo en instancias tempranas del proceso. Entonces pueden ser abordados de inmediato. Esta decisión es muy relevante para evitar posibles crisis, ya que cualquier característica “conflictiva” será eliminada o corregida a tiempo.
En conclusión, has aprendido todos los detalles del Desarrollo Rápido de Aplicaciones y ahora sabes por qué es tan importante integrarlo en tus desarrollos. ¡Esperamos que te haya gustado este artículo!

por Huenei IT Services | Apr 27, 2021 | Infra, Process & Management
Introducción
En el artículo Conceptos clave sobre Data Lakes, hablamos sobre su importancia, arquitectura y los comparamos con un Data Warehouse. En esta entrega, nos enfocaremos en su implementación usando Amazon Web Services (AWS), la plataforma cloud de Amazon. Veremos el flujo general, los distintos servicios disponibles y, por último, AWS Lake Formation, una herramienta especialmente diseñada para facilitar esta tarea.
Flujo general
Un Data Lake respalda las necesidades de nuestras aplicaciones y analíticas, sin que debamos preocuparnos constantemente por el aumento de recursos de almacenamiento y cómputo, a medida que la empresa crece y la cantidad de datos aumenta. Sin embargo, no existe una fórmula mágica para su creación. Generalmente, implica el uso de docenas de tecnologías, herramientas y entornos. En el siguiente diagrama, se puede observar el flujo general de datos, desde la recopilación, el almacenamiento y el procesamiento, hasta el uso de las analíticas mediante técnicas de Machine Learning y Business Intelligence.
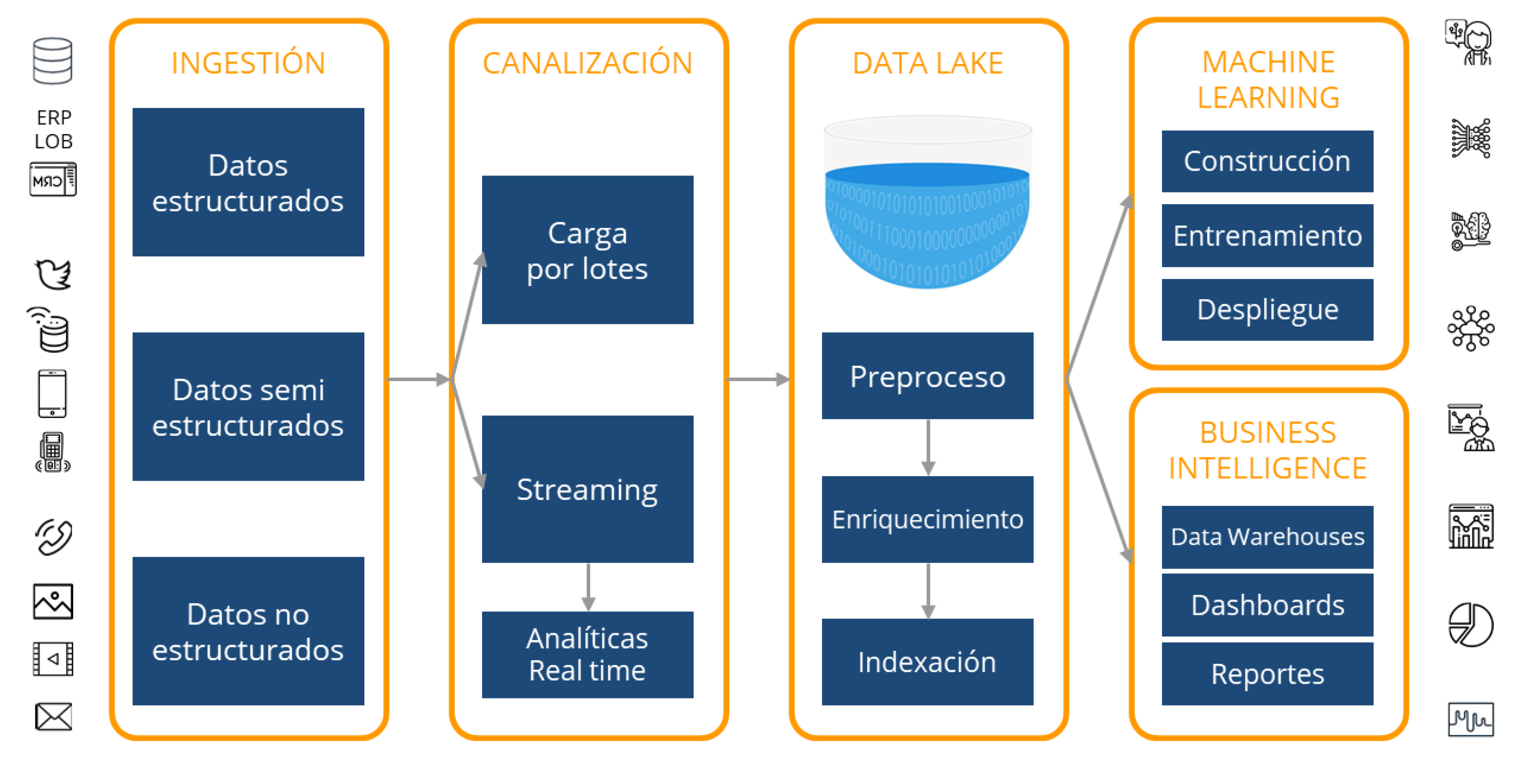
Servicios disponibles en AWS
AWS brinda un amplio conjunto de servicios administrados que ayudan a constituir un Data Lake. Es necesaria una planificación y diseño adecuados para migrar un ecosistema de datos a la Nube, y para ello es fundamental comprender la oferta de Amazon. Aquí haremos mención de solo algunas de las herramientas más importantes en cada etapa del flujo.
Ingestión
El primer paso es analizar los objetivos y beneficios que se desean lograr con la implementación de un Data Lake basado en AWS. Una vez diseñado el plan, se deben migrar los datos a la Nube, teniendo en cuenta el volumen de los mismos. Es posible acelerar fácilmente esta migración con servicios como Snowball y Snowcone (dispositivos edge para almacenamiento y cómputo) o DataSync y Transfer Family, para simplificar y automatizar transferencias.
Canalización
En este paso, se puede operar de 2 modos: por Lotes o por Streaming.
En la Carga por Lotes, se utiliza AWS Glue para extraer información de varias fuentes, en intervalos periódicos, y moverlos al Data Lake. Normalmente implica alguna transformación mínima (ELT), como la compresión o la agregación de datos.
En el caso de trabajar con Streaming, se ingieren datos generados continuamente a partir de múltiples fuentes, como archivos de logging, telemetría, aplicaciones móviles, sensores IoT y redes sociales. Se pueden procesar durante una ventana de tiempo circular y canalizar el resultado al Data Lake.
Las Analíticas en tiempo real brindan información útil para procesos de negocio críticos que dependen del análisis de datos en streaming, como algoritmos de Machine Learning para la detección de anomalías. Amazon Kinesis Data Firehose (servicio gestionado para streaming) ayuda a realizar este proceso desde cientos de miles de orígenes en tiempo real, en lugar de cargar datos durante horas y procesarlos luego.
Almacenamiento y Procesamiento
En un Data Lake de AWS el servicio más importante de todos es Amazon S3, que brinda almacenamiento de alta escalabilidad, excelentes costos y niveles de seguridad, ofreciendo así una solución integral para llevar a cabo diferentes modelos de procesamiento. Puede almacenar datos ilimitados y cualquier tipo de archivo como un objeto. Permite crear tablas lógicas y jerarquías a partir de carpetas (por ejemplo, por año, mes y día), permitiendo la partición de datos en volumen. También ofrece un amplio conjunto de funciones de seguridad, como controles y políticas de acceso, cifrado en reposo, registro, monitoreo, entre otros. Una vez que los datos se cargan, pueden usarse en cualquier momento y en lugar, para afrontar cualquier necesidad. Cuenta con una amplia gama de clases de almacenamiento (Estándar, Inteligente, Acceso poco frecuente), cada una con diferentes capacidades, tiempos de recuperación, seguridad y costo.
AWS Glacier es un servicio para el archivado seguro y la gestión de copias de seguridad, a una fracción del costo de S3. Las recuperaciones de archivos pueden demorar de pocos minutos a 12 horas, dependiendo de la clase de almacenamiento seleccionada.
AWS Glue es un servicio administrado de ETL y Catálogo de Datos que ayuda a encontrar y catalogar metadatos para realizar consultas y búsquedas más rápidas. Una vez que Glue apunta a los datos almacenados en S3, los analiza mediante rastreadores automáticos y registra su esquema. El propósito de Glue es realizar transformaciones (ETL/ELT) usando Apache Spark, scripts Python y Scala. Glue no tiene servidor; por lo tanto, no hay ninguna infraestructura configurada, lo que lo hace más eficiente.
Si se requiere una indexación de los contenidos del Data Lake, puede utilizarse AWS DynamoDB (base de datos NoSQL) y AWS ElasticSearch (servidor de búsqueda de texto). Además, mediante el uso de funciones AWS Lambda, activadas directamente por S3 en respuesta a eventos como la carga de nuevos archivos, pueden dispararse procesos para mantener su Catálogo actualizado.
Analíticas para Machine Learning y Business Intelligence
Hay varias opciones para obtener información de forma masiva del Data Lake.
Una vez que los datos han sido catalogados por Glue, se pueden utilizar diferentes servicios en la capa de cliente para analíticas, visualizaciones, dashboards. etc. Por ejemplo, Amazon Athena, un servicio serverless interactivo para consultas exploratorias ad hoc utilizando SQL estándar; Amazon Redshift, un servicio Data Warehouse para consultas e informes más estructurados; Amazon EMR (Amazon Elastic MapReduce), un sistema administrado para herramientas de procesamiento Big Data como Apache Hadoop, Spark, Flink, entre otras; y Amazon SageMaker, una plataforma de aprendizaje automático que permite a los desarrolladores crear, entrenar e implementar modelos de Machine Learning en la nube.
Con Athena y Redshift Spectrum, se puede consultar directamente el Data Lake en S3 utilizando el lenguaje SQL, a través del Catálogo de AWS Glue, que contiene metadatos (tablas lógicas, esquema, versiones, etc.). El punto más importante es que sólo se paga por las consultas ejecutadas, en función de la cantidad de datos escaneados. Por lo tanto, puede lograr significantes mejoras en el desempeño y el costo al comprimir, dividir en particiones o convertir sus datos en un formato de columna (como Apache Parquet), ya que cada una de esas operaciones reduce la cantidad de datos que Athena o Redshift Spectrum deben leer.
AWS Lake Formation
Construir un Data Lake es una tarea compleja, de varios pasos, entre ellos:
- Identificar fuentes (Bases de Datos, archivos, streams, transacciones, etc.).
- Crear los buckets necesarios en S3 para almacenar estos datos, con sus correspondientes políticas.
- Crear los ETLs que realizarán las transformaciones necesarias y la correspondiente administración de políticas de auditoría y permisos.
- Permitir que los servicios de Analíticas accedan a la información del Data Lake.
AWS Lake Formation es una opción atractiva que permite a usuarios (tanto principiantes como expertos) comenzar de manera inmediata con un Data Lake básico, abstrayendo los detalles técnicos complejos. Permite monitorear en tiempo real desde un único punto, sin necesidad de recorrer múltiples servicios. Un aspecto fuerte es su costo: AWS Lake Formation es gratis. Sólo se cobrará por los servicios que se invoquen a partir de él.
Permite la carga de diversas fuentes, monitorizar esos flujos, configurar particiones, activar el cifrado y gestión de claves, definir trabajos de transformación y monitorearlos, reorganizar datos en formato columnar, configurar el control de acceso, deduplicar datos redundantes, relacionar registros vinculados, obtener acceso y auditar el acceso.
Conclusiones
En estos 2 artículos, conocimos que es un Data Lake, qué lo hace diferente a un Data Warehouse y cómo se podría implementar en la plataforma de Amazon. Es posible reducir significativamente el CTO moviendo su ecosistema de datos a la nube. Proveedores como AWS agregan nuevos servicios continuamente, mientras mejoran los existentes, reduciendo los costos de los mismos.
Huenei puede ayudarlo a planificar y ejecutar su iniciativa de Data Lake en AWS, en el proceso de migración de sus datos a la nube y la implementación de las herramientas de Analíticas necesarias para su organización.

por Huenei IT Services | Mar 26, 2021 | Infra, Process & Management
Los datos se han convertido en un elemento vital para las empresas digitales, y una ventaja competitiva clave, pero el volumen de datos que actualmente necesitan administrar las organizaciones es muy heterogéneo y su velocidad de crecimiento exponencial. Surge así la necesidad de soluciones de almacenamiento y análisis, que ofrezcan escalabilidad, rapidez y flexibilidad para poder gestionar esta masiva cantidad de datos. ¿Cómo es posible almacenarlos de manera rentable y acceder a ellos rápidamente? Un Data Lake (Lago de Datos) es una respuesta moderna a este problema.
En esta serie de artículos, veremos qué es un Data Lake, cuáles son sus beneficios y cómo podemos implementarlo utilizando Amazon Web Services (AWS).
¿Qué es un Data Lake?
Un Data Lake es un repositorio de almacenamiento centralizado, que permite guardar todo tipo de datos estructurados o no, a cualquier escala, sin procesar, hasta que se los necesite. Cuando surge una pregunta de negocio, es posible obtener la información relevante y ejecutar diferentes tipos de análisis sobre ella, a través de dashboards, visualizaciones, procesamiento de Big Data y aprendizaje automático, para guiar la toma de mejores decisiones.
Un Data Lake puede almacenar datos tal como están, sin tener que estructurarlos primero, con poco o ningún procesamiento, en sus formatos nativos, tales como JSON, XML, CSV o texto. Puede almacenar tipo de archivos: imágenes, audios, videos, weblogs, datos generados desde sensores, dispositivos IoT, redes sociales, etc. Algunos formatos de archivo son mejores que otros, como Apache Parquet que es un formato columnar comprimido que proporciona un almacenamiento muy eficiente. La compresión ahorra espacio en disco y accesos de E/S, mientras que el formato permite al motor de consultas escanear sólo las columnas relevantes, lo cual reduce el tiempo y los costos de las mismas.
El uso de un sistema de archivos distribuido (DFS), como AWS S3, permite almacenar más datos a un costo menor, brindando múltiples beneficios:
- Replicación de datos
- Altísima disponibilidad
- Bajos costos, con diferentes escalas de precios y múltiples tipos de almacenamiento dependientes del tiempo de recuperación (desde acceso instantáneo a varias horas)
- Políticas de retención, lo que permite especificar cuánto tiempo conservar los datos antes de que se eliminen automáticamente
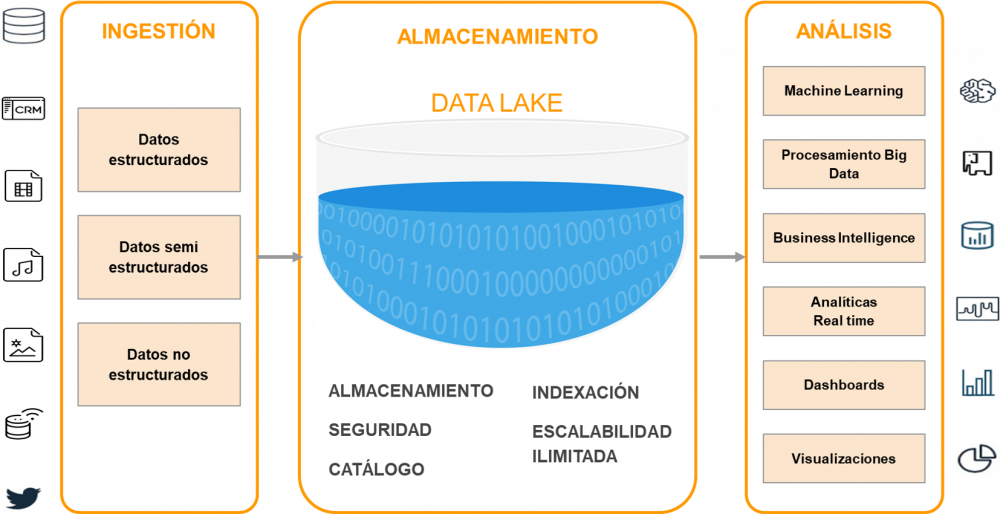
Data Lake versus Data Warehouse
Los Data Lakes y los Data Warehouses son dos estrategias diferentes de almacenar Big Data, en ambos casos sin atarse a una tecnología específica. La diferencia más importante entre ellos es que, en un Data Warehouse, el esquema de datos está preestablecido; se debe crear un esquema y planificar las consultas. Al alimentarse de múltiples aplicaciones transaccionales en línea, se requiere que los datos se transformen vía ETL (extraer, transformar y cargar) para que se ajusten al esquema predefinido en el almacén de datos. En cambio, un Data Lake puede albergar datos estructurados, semi-estructurados y no estructurados y no tiene un esquema predeterminado. Los datos se recogen en estado natural, necesitan poco o ningún procesamiento al guardarlos y el esquema se crea durante la lectura para responder a las necesidades de procesamiento de la organización.
El Data Lake es una solución más flexible y adaptada a usuarios con perfiles más técnicos, con necesidades de análisis avanzadas, como Científicos de Datos, porque se necesita un nivel de habilidad para poder clasificar la gran cantidad de datos sin procesar y extraer fácilmente el significado de ellos. Un almacén de datos se centra más en usuarios de Análiticas de Negocios, para respaldar las consultas comerciales de grupos internos específicos (Ventas, Marketing, etc.), al poseer los datos ya curados y provenir de los sistemas operacionales de la empresa. Por su parte, los Data Lakes suelen recibir datos tanto relacionales como no relacionales de dispositivos IoT, redes sociales, aplicaciones móviles y aplicaciones corporativas.
En lo que respecta a la calidad de los datos, en un Data Warehouse, estos están altamente curados, son confiables y se consideran la versión central de la verdad. En cambio, en un Data Lake son menos confiables porque podrían llegar de cualquier fuente en cualquier estado, curados o no.
Un Data Warehouse es una base de datos optimizada para analizar datos relacionales, provenientes de sistemas transaccionales y aplicaciones de línea de negocios. Suelen ser muy costosos para grandes volúmenes de datos, aunque ofrecen tiempos de consulta más rápidos y mayor rendimiento. Los Data Lakes, en cambio, están diseñados pensando en el bajo costo de almacenamiento.
Algunas críticas legítimas que reciben los Data Lakes son:
- Es aún una tecnología emergente frente el modelo de madurez fuerte de un Data Warehouse, el cual posee muchos años en el mercado.
- Un Data Lake podría convertirse en un “pantano”. Si una organización practica una deficiente gestión y gobernanza, puede perder el rastro de lo que existe en el “fondo” del lago, provocando su deterioro, volviéndolo incontrolado e inaccesible.
Debido a sus diferencias, las organizaciones pueden optar por utilizar tanto un Data Warehouse como un Data Lake en una implementación híbrida. Una posible razón sería el poder agregar nuevas fuentes o usar el Data Lake como repositorio para todo aquello que ya no se necesite en el almacén de datos principal. Con frecuencia, los Data Lakes son una adición o una evolución de la estructura de administración de datos actual de una organización en lugar de un reemplazo. Los Analistas de Datos pueden hacer uso de vistas más estructuradas de los datos para obtener sus respuestas y, a la vez, la Ciencia de Datos puede «ir al lago» y trabajar con toda la información en bruto que sea necesaria.
Arquitectura de un Data Lake
La arquitectura física de un Data Lake puede variar, ya que se trata de una estrategia aplicable por múltiples tecnologías y proveedores (Hadoop, Amazon, Microsoft Azure, Google Cloud). Sin embargo, hay 3 principios que lo distinguen de otros métodos de almacenamiento Big Data y constituyen la arquitectura básica de un Data Lake:
- No se rechaza ningún dato. Se cargan desde varios sistemas de origen y se conservan.
- Los datos se almacenan en un estado sin transformar o casi sin transformar, tal como se recibieron de la fuente.
- Los datos se transforman y se ajustan al esquema durante el análisis.
Si bien la información, en gran medida, no está estructurada ni orientada a responder una pregunta específica, debe ser organizada de alguna manera, para garantizar que el Data Lake sea funcional y saludable. Algunas de estas características incluyen:
- Etiquetas y/o metadata para la clasificación, que puede incluir tipo, contenido, escenarios de uso y grupos de posibles usuarios.
- Una jerarquía de archivos con convenciones de nomenclatura.
- Un Catálogo de datos indexado y con capacidad de búsqueda.
Conclusiones
Los Data Lakes son cada vez más importantes para las estrategias de datos empresariales. Responden mucho mejor a la realidad actual: volúmenes y tipos de datos mucho mayores, mayores expectativas de los usuarios y mayor variedad de analíticas, tanto de negocio como predictivas. Tanto los Data Warehouses como los Data Lakes están destinados a convivir en las empresas que deseen basar sus decisiones en datos. Ambos son complementarios, no sustitutivos, pudiendo ayudar a cualquier negocio a conocer mejor el mercado y al consumidor, e impulsar iniciativas de transformación digital.
En el próximo artículo, analizaremos cómo podemos utilizar Amazon Web Services y su infraestructura abierta, segura, escalable y rentable, para construir Data Lakes y analíticas sobre ellos.
