
In a world full of information, organizations feed on data to make all kinds of decisions. Whether operational or strategic resolutions, decisions on logistics, marketing, or finance, data takes a crucial role in this process. The awareness and use of customer data management systems, management information systems, and big data is growing. But data management is not an easy task. Data is stored and manipulated in databases. We can understand that databases, then, represent a fundamental pillar for companies. A correctly-designed database offers customers admission to crucial information. By following the standards and best practices we’ll discuss in this article, you’ll be able to layout a database graph that works nicely and fits your organization’s needs.
What are the components of databases?
Databases are made up of different elements that give life to the interactions between data. We can identify three major components of a database:
1. On the one hand, tables represent a set of homogeneous data with a defined structure. Data is organized into fields (also known as columns) and records (also called rows). Having different tables within a database can be very useful since its correct administration helps to avoid data redundancy and to optimize processes.
2. As the second fundamental pillar of database management, we must mention the relationships between tables. These relationships are links to one or more tables from a field that they share. This field, generally called a key, can represent an identification that allows recognizing the specific record that each row represents. In this way, it is possible to combine different tables to take advantage of their interrelationships.
3. Last but not least, we have the normalization of databases. It is a necessary process for a database to be used optimally. Thanks to it, we can focus on avoiding data redundancy and guaranteeing their referential integrity. Normalization is the process that allows one table to communicate with another and for the data and information type to be compatible. It can also help us to interconnect different databases to take advantage of their joint management.
The interactions between the tables occur thanks to relational algebra. These are all the logical and mathematical operations that work at the back end of a database management system. It allows us to create a relationship between tables, allowing us to retrieve data efficiently.
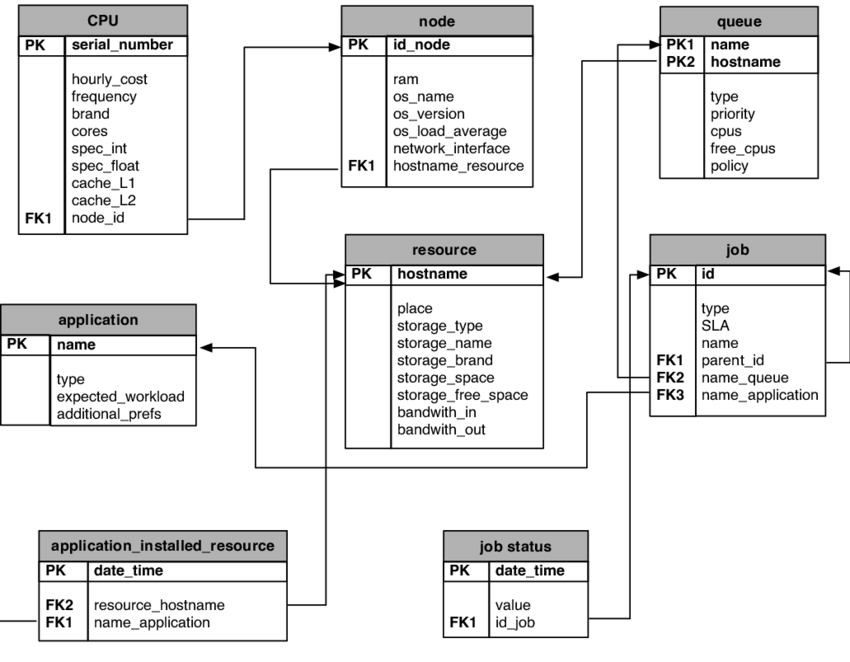
Relational Schema and how to design databases.
A relational Schema is a graphical representation that allows a data architect to have a reliable idea of how the database must be organized. It is a super useful graphic in the process of planning the structure of a database. It is made up of the tables, the interactions between them, and the different keys that allow them to be used together.
To build a relational schema, we must indicate the following elements on the graph:
- Each table, represented as an individual rectangle. For example, a company might have one table with product information, one with customer information, one with production costs, one with sales costs, and one with sales information. These five tables could interact in a database.
- Each column of each table, which will be a line within each square. For example, in a table with product information, we might have the following columns: product ID, product name, product brand, product type, product color, and product size.
- The primary keys. This is a column (or set of columns) whose value exists and is unique for every record in a table. Surely, reading the concept of the primary key, you can imagine that a common example is the ID of a product or a customer.
- The foreign keys. These are columns that identify the relationship between tables. Generally, the primary key of one table is used as the foreign key of another. For example, a table with sales information can use the product ID column as a foreign key to look up product information in another table.
- The relationships between the columns, that tell you how much of the data from a foreign key field can be seen in the primary key column of the table that the data is related to.
- The types of relationships:
- One-to-many: one value from a column under a certain table can be found many times in a column from another table.
- One-to-one: each unique value of a column of a table can only appear once in a certain column of another table.
- Many-to-many: there is no restriction on the number of times the values can be repeated.
It seems very complicated, but with a little practice, a developer becomes adept at creating databases using this tool. At Huenei we always structure the databases of our projects using relational schemas, since they help us to enhance the operation of our software products.
As you can see, the correct management of these databases could allow a company to reduce the redundancy and inconsistency of data, reduce the difficulty for interested parties to access them, avoiding data isolation. Additionally, database administration focuses on correcting anomalies in concurrent access, reducing security problems, and also data integrity and consistency.
Relational schemas help software factories achieve smoother and more efficient development!